Uptime
Uptime is the amount of time a server has been in continuous proper operation without needing a reboot. When I was working a nine to five and managing datacenters, servers, and networks, a quick and easy way to determine a servers health was to check it’s “uptime”. In fact I setup my command line accounts to automatically display the uptime upon login. I always got a kick out of logging into a server and discovering it had an uptime of a year or more. In the scheme of things this is not as rare as it seems and it says a lot about the stability and reliability of the running operating system, the error free operation of the application, and finally proper climate controls including temperature and humidity of the servers or datacenters physical operating environment. Such long uptimes take on new meaning when it’s realized that not only has the server been up for a year, but the electricity which provides the power to keep the server running also has not been interrupted. This is not as surprising in production environments as there are redundancies in place to keep power going such as Uninterruptible Power Supplies (UPS) and diesel generators in case of electrical grid failure. You get a big bang for your buck when systems operate continuously without error.
There’s a story out of berkeley.edu that says back in the 80’s some department was expanding it’s available office space by augmenting contiguous rooms and tearing out the intervening wall. On the day the electrician comes and starts ripping out drywall to get to the guts of the electrical system, a small cavity is found behind the wall. After ripping out enough of the drywall to access the cavity, a computer with an ancient green screen monochrome monitor attached had been “walled” in and was sitting in this cubby hole with a welcoming login prompt. It was discovered that this system had over 10 years of continuous uptime and was a subsystem critical to the proper operation of the berkeley.edu network infrastructure. It was the primary DNS server resolving domain name requests for the internal berkeley.edu network, which is massive in it’s own right. The other surprising thing is that the system was known because domain names would have to be updated on a regular basis so someone was regularly administering the machine by entering new IP (Internet Protocol) to server name mappings and reverse zone mappings (from time to time as new servers come online, old servers go offline), as well as updating the backend bind DNS software. Yet no one at Berkeley could tell you where this server was physically located and at this point probably didn’t care. That’s pretty impressive by any means and could be a type of guarantee, though rather extreme, of what might be written into what’s known as an SLA (Service Level Agreement).
SLA’s (Service Level Agreement)
Service Level Agreements (SLA’s) are contracts either between vendors, technical support, or even between departments which sets standards for the availability of resources and/or services offered. For example, let’s say an online business needs to be operating 24×7 and have at a minimum 10 gigabits of bandwidth to handle continuous web page requests plus “burst” speeds of up to 100 gigabits to keep pace with a growing user base as well and have extra capacity during times of peak usage. This might be guaranteed in writing via an SLA.
Should the service or resource for whatever reason fail to achieve these guarantees, the SLA may even contain provisions to address the service interruption. With repercussions ranging from reduced cost service to free service to the ability to bill the service provider, or even satisfy a money judgement in the case the breach of SLA caused monetary shortcomings. So here we’re talking about downtime incurred and one of the ways to address how much downtime has been accrued or even projected is to use the system of nines (9’s).
The Nines
The system of nines is a percentage based system that represents how much downtime, or conversely, how much uptime, a service provider must provide as a sort of waiver against interruptions in service or resources. Conditions exist which might be outside the control of the service provider such as acts of God, customer error, or even infrastructure upgrade. In essence, to guarantee some resource or service will be available and functioning so as not to impact the business receiving the resource or service. An SLA might be measured by what is known colloquially as the system of nines. Terms such as a “five nines” guarantee, or 99.999% of uptime allow only for 5 minutes of downtime in a single year. This might seem like an impossible task however disruption of resource or services might also be a scheduled affair and likely to be written out in the SLA. Scheduled outages either by vendor or consumer may not be counted as long as there is a provision for that.
Technical support available to consumers of digital products. Additional hardware to be stocked in the case of failures. The guarantee of a measured amount of bandwidth available to the consumers of that bandwidth with provisions for peak periods and consumer growth as noted above. Examples of the consumption of any resource might be measured on the system of nines (9’s as described by the following table:

- 99.9% – 3 Nines = 36.53 days
- 99.99% – 4 Nines = 3.65 days
- 99.999% – 5 Nines = 5 Minutes
The above statistics point out the amount of downtime a given resource or service might be unavailable during the course of one year. Just in case you don’t think four 9’s or five 9’s of continuous service to be unrealistic, think about telecommunications networks, worldwide banking networks, or even the electrical grid which are types of services where it is common to see guarantees of four 9’s or five 9’s written into agreements and SLA’s.
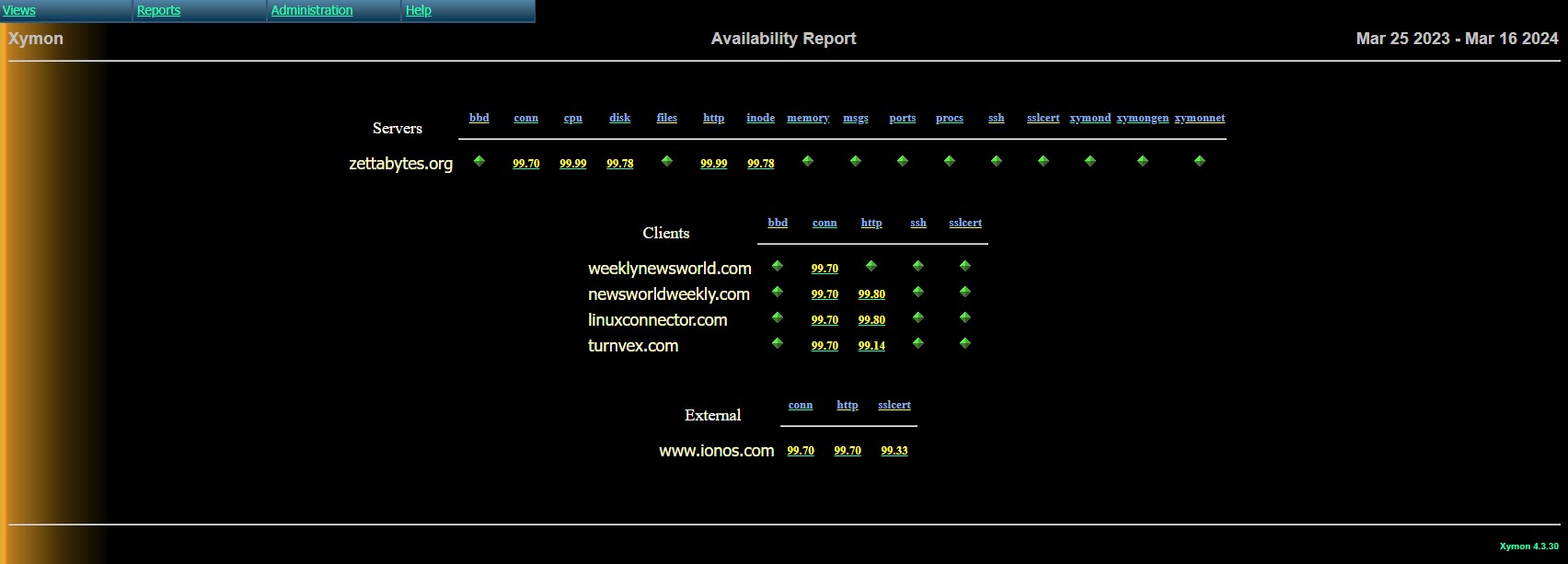
My Performance Over 1 Year
The picture which heads this article is a page from the Xymon system/service monitor for the domains I manage, with percentages of uptime based on the system of nines. The Xymon system and network monitor is core application I maintain and administrate which also can track various statistics over time. I’m particularly proud of the http statistic at “four 9’s” which shows that over the course of a year one of my primary servers has incurred less than 3.65 days downtime over the course of a year. I’m a systems engineer and consultant and I maintain all of the hardware, plus the software which is comprised of the Apache version 2 web server, the PHP application server (I support versions 7 and 8), and finally the MySQL version 8.x.x database server. I also maintain the Xymon service monitoring hardware which is where the pictured statistics originate.
In summary, uptime, SLA’s, and the system of nines give service providers and consumers piece of mind and the confidence to know systems, services, and their resources are operating within the tight tolerances they are expecting.
Thanks for taking the time to read this. Please consider a donation if you like what we do.
Leave a Reply